相关技术
Microsoft 365 Copilot
Copilot Studio
Azure AI Foundry
GitHub Copilot
Azure Open Al
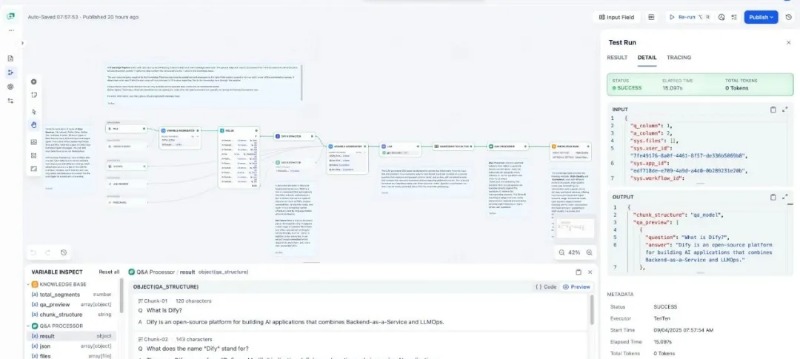
Dify
相关技术
Microsoft 365
Microsoft 365 Teams and Teams Phone
Microsoft 365 移动和安全套件
Microsoft Azure
Microsoft Entra ID
Microsoft Security
相关技术
NovaFlow BPM引擎
Microsoft Dynamics 365 BC
Microsoft Dynamics 365 CRM
Microsoft Power Apps
Microsoft Power Automate
Microsoft Power BI
相关技术
诺未服务中心
诺未支持团队
ITIL运维工具

上海诺未亮相微软AI Tour,深耕微软生态,共启企业智能体时代新篇章
公司动态
上海诺未亮相微软AI Tour,深耕微软生态,共启企业智能体时代新篇章
2026.04.22